Web service requests via snakes and spiders
First off, hope you are all enjoying Drupalcon, super jealous.
Its been almost three months since I wrote about Creating secure, low-level bootstraps in D7, the gist of which is skipping index.php when you make webservice calls so that Drupal doesn't have to bootstrap as high. Now that I've been playing with this, we've been starting to work on a series of simplied calls that can propagate data across the network in different ways.
For example, if data that's in one system but cached in another is updated, I can tell all the other systems of that type to have their cache wiped. This is a series of Services and Authority systems making up ELMS:LN and they form different patterns. The most common use-case though that's easiest to grasp is updating a course name.
Let's say we have a course named 'Stuff' and we want to make it now called 'Stuff 100'. Well, that simple node with title 'Stuff', actually lives in anywhere from 10 to 15 systems depending on the structure of the network it's related to. Similarly, we don't know where the data is being updated (potenitally) and we don't want to force people to only be allowed to update it in one place.
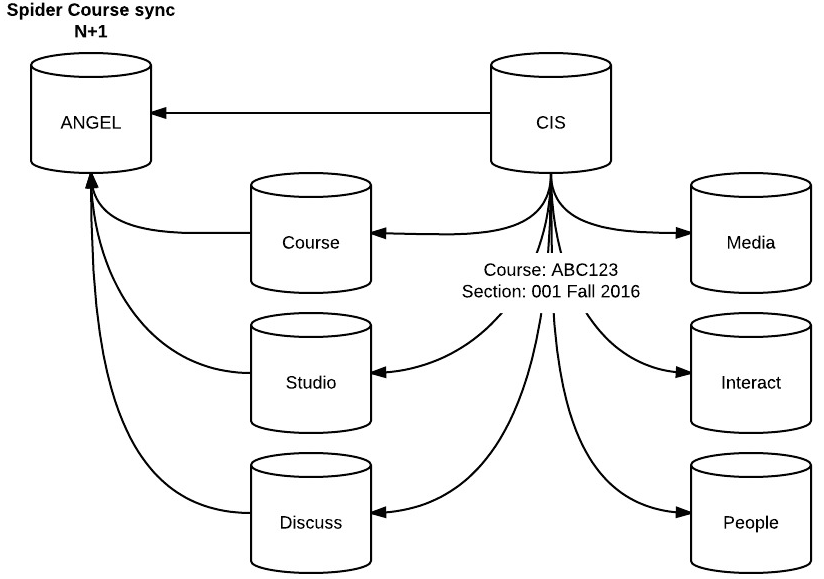
Spider
We could spider the call (and originally were). This assumes figuring out the 10 or so places you want to send data and then sending it to all of them at once (or one then the next, etc). This invokes (N+1) load though as we use non-blocking httprl based calls, meaning that 10 calls will open 10 simultaneous apache / php-fpm threads. That's a lot of network traffic when starting to scale up, invoking self imposed spikes. We still need this call to go everywhere though so we need to borrow a concept from Twitter.
Snake
When you send a tweet, it doesn't go to 1 massive database which then everyone reads from, it goes to localized databases and then every X number of seconds, messages are passed to neighbors in the twitter network. You can try this out yourself if you VPN to another part of the world then send a tweet and see how long it takes to show up in someone's timeline sitting next to you vs doing it on the same network.
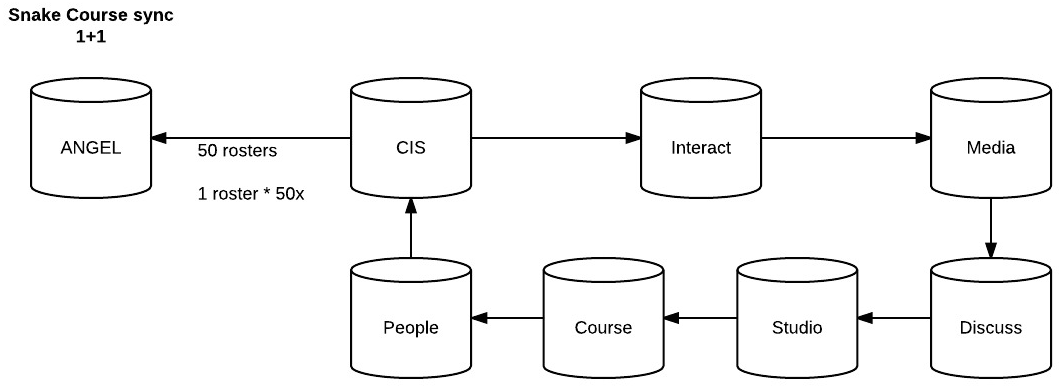
For this call, we still send non-blocking and we still send to everyone in the network, but we use distributed recursion in order to accomplish it. Basically site A figures out "I have data that needs to go to these 9 systems". Then it sends the message as well as the list of the next 8 systems over to system B. B then looks, processes the request and JUST before finishing the connect says "wait, do I have others to pass this on to?" and see the 8 systems in the list. It then sees the first one as who to contact next then sends the stack of 7 systems who will also need the call. This process repeates recursively until there are no more calls (at which point I'm thinking of adding a "bite tail" function to call the originator and say it finished).
So that's cool but why do we care?
We care because this doesn't invoke N+1 load even though it's still replicated the message across N+1 systems! The snake methodology of data propegation will keep 2 apache / php-fpm threads open at any one time.
System A calls B (non-blocking call, A hangs up and delivers you the end user the page)
System B calls C (non-block call, B hangs up, you have no idea this is happening)
System C calls D (non-block call, C hangs up, recursively til no more stack to call)
Snake will always invoke at most 2 execution threads instead of N+1 which is a huge performance and scale gain. The difference to the end user is marginal as everything is non-block either way. Just make sure that you correctly block recursive kick offs on `hook_node_update` or you'll get something funny (and crippling) like this issue write up.
Code example for the function testing if it should ship off to the next member of the network:
// look for snake calls which we can perform on anything stupid enough
// to attempt it. This can destroy things if not done carefully
if (isset($_elmsln['args']['__snake_stack']) && !empty($_elmsln['args']['__snake_stack'])) {
// tee up the next request as well as removing this call
// from our queue of calls to ship off
while (!isset($path)) {
$bucket = array_pop($_elmsln['args']['__snake_stack']);
$systype = _cis_connector_system_type($bucket);
switch ($systype) {
case 'service':
$path = '/' . $_elmsln['args']['__course_context'] . '/';
break;
case 'authority':
$path = '/';
break;
default:
// support for skipping things outside authority / service scope
break;
}
}
// need to queue module / callback back up for the resigning of the request
$_elmsln['args']['elmsln_module'] = $_elmsln['module'];
$_elmsln['args']['elmsln_callback'] = $_elmsln['callback'];
$version = str_replace('v', '', $_elmsln['args']['q']);
// issue call now against the next item in the stack
$request = array(
'method' => strtoupper($method),
'api' => $version,
'bucket' => $bucket,
'path' => $path,
'data' => $_elmsln['args'],
);
// request the next item while indicating that recursive calls are allowed
// so that it gets passed down the snake
_elmsln_api_request($request, TRUE, TRUE);
}
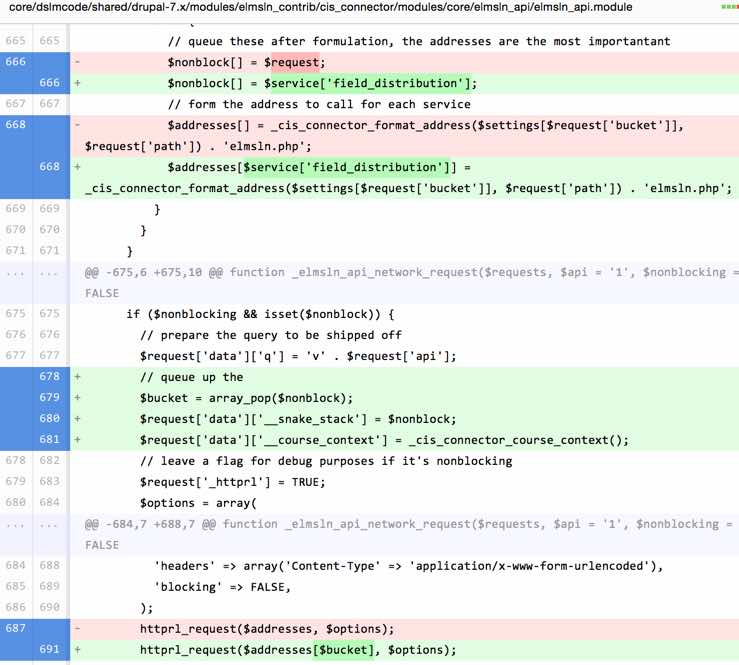
Here's a screenshot of the code diff that it not takes for us to switch off of traditional non-blocking spidered calls to non-blocking snake calls. 8 lines of code for me to switch from Spider to Snake.